Natural Language Triggers
Triggers initiate a plugin in Assistant. Plugin can either be triggered through a user's natural language utterance or proactively through a system event.
Setup natural language intents
To create Creator Studio plugins that trigger through natural language you need to:
- Setup names & descriptions for your plugins &
- Setup positive & negative triggering examples.

Will my positive triggering examples always trigger?
Generally your positive examples should trigger & your negative examples shouldn't trigger the plugin but this is not guaranteed.
Moveworks trains "triggering intents" using your plugin descriptions & triggering examples. These intents stand for a precise decision boundary of user utterances for which this plugin should be relevant. For a deepdive on intents read the next section.
How to write good triggering examples
You should:
- Add triggering examples that span a few diverse examples.
- Never add the same / semantically identical triggering examples as both positive or negative examples for the same plugin.
Additionally, depending on your situation you should either add positive or negative triggering examples.
| Situation | What you should do |
|---|---|
| Plugin is not triggering for expected utterances | ✅ Then, add some of these utterances as positive examples |
| Two or more similar plugins have overlapping triggering | ✅ Then, add the same utterances as positive examples for 1 utterance & negative examples for the other(s). This clarifies the plugin intent boundaries for Assistant. |
| Plugin is overtriggering or it shouldn't trigger for certain scenarios | ✅ Then, add these utterances as negative examples. |
Deepdive: Generative Intents
Moveworks builds a generative intent for your plugins, on-the-fly.
 First, we use all the plugin configurations, and use
First, we use all the plugin configurations, and use GPT to generate synthetic utterances that make sense for these stories.Second, we use an in-house enterprise-language clustering model called MPNet to retrieve similar utterances from your production traffic.Third, we combine those production utterances with GPT to produce samples that are near your decision boundary. All you do is tell us if we're getting warmer or colder. 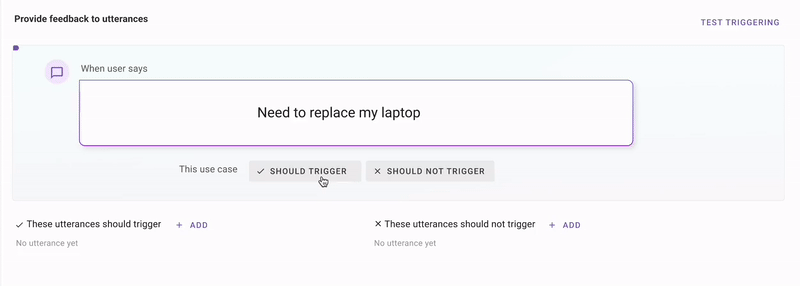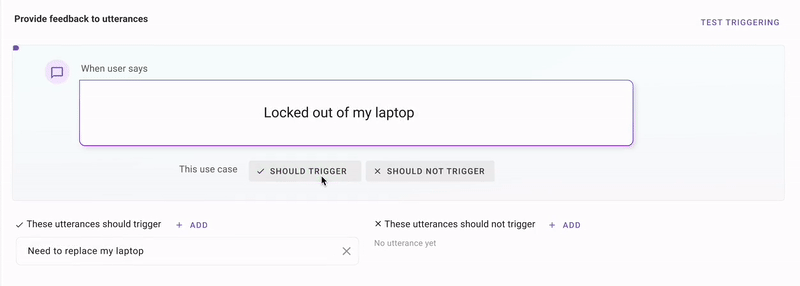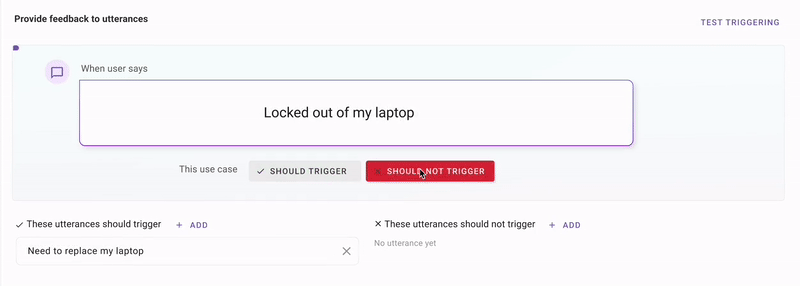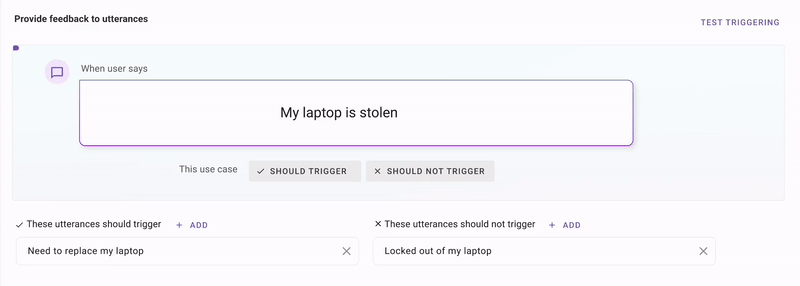
This is a technique called discriminative modeling. It's similar to what happens in Google Photos when it shows you a picture of your friend and asks “Is this the same person 4-5 times, and then it knows how to identify that person in 1000 more pictures.
 Fourth, we tune a
Fourth, we tune a T0 classifier, which is zero-shot, generative LLM with 11B parameters. T0 is based on Flan-T5 which outperforms GPT on domain classification tasks.After tuning, we continuously benchmark performance to give you the best enterprise language model experience.